Author: Krishnakumar R (KK) (Microsoft), Pengfei Ni (Microsoft)
Introduction
With Kubernetes v1.12, Azure virtual machine scale sets (VMSS) and cluster-autoscaler have reached their General Availability (GA) and User Assigned Identity is available as a preview feature.
Azure VMSS allow you to create and manage identical, load balanced VMs that automatically increase or decrease based on demand or a set schedule. This enables you to easily manage and scale multiple VMs to provide high availability and application resiliency, ideal for large-scale applications like container workloads [1].
Cluster autoscaler allows you to adjust the size of the Kubernetes clusters based on the load conditions automatically.
Another exciting feature which v1.12 brings to the table is the ability to use User Assigned Identities with Kubernetes clusters [12].
In this article, we will do a brief overview of VMSS, cluster autoscaler and user assigned identity features on Azure.
VMSS
Azure’s Virtual Machine Scale sets (VMSS) feature offers users an ability to automatically create VMs from a single central configuration, provide load balancing via L4 and L7 load balancing, provide a path to use availability zones for high availability, provides large-scale VM instances et. al.
VMSS consists of a group of virtual machines, which are identical and can be managed and configured at a group level. More details of this feature in Azure itself can be found at the following link [1].
With Kubernetes v1.12 customers can create k8s cluster out of VMSS instances and utilize VMSS features.
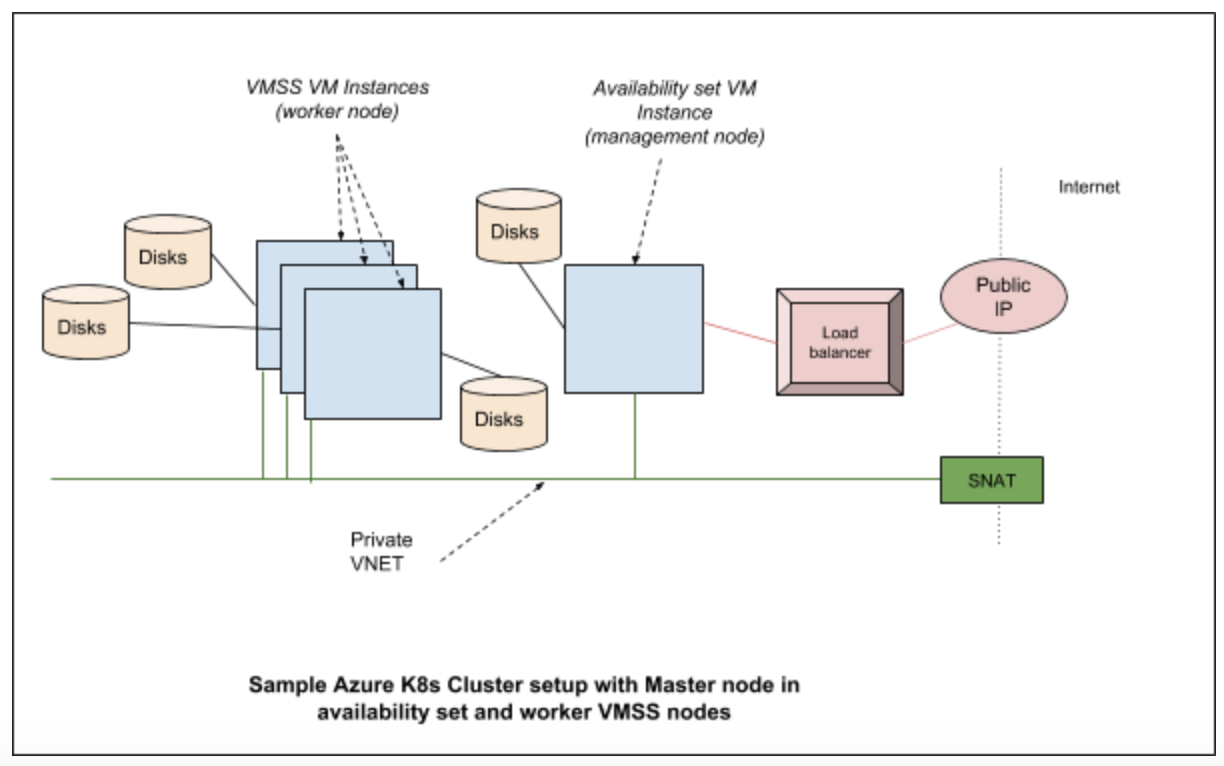
Cluster components on Azure
Generally, standalone Kubernetes cluster in Azure consists of the following parts
- Compute – the VM itself and its properties.
- Networking – this includes the IPs and load balancers.
- Storage – the disks which are associated with the VMs.
Compute
Compute in cloud k8s cluster consists of the VMs. These VMs are created by provisioning tools such as acs-engine or AKS (in case of managed service). Eventually, they run various system daemons such as kubelet, kube-api server etc. either as a process (in some versions) or as a docker container.
Networking
In Azure Kubernetes cluster various networking components are brought together to provide features required for users. Typically they consist of the network interfaces, network security groups, public IP resource, VNET (virtual networks), load balancers etc.
Storage
Kubernetes clusters are built on top of disks created in Azure. In a typical configuration, we have managed disks which are used to hold the regular OS images and a separate disk is used for etcd.
Cloud provider components
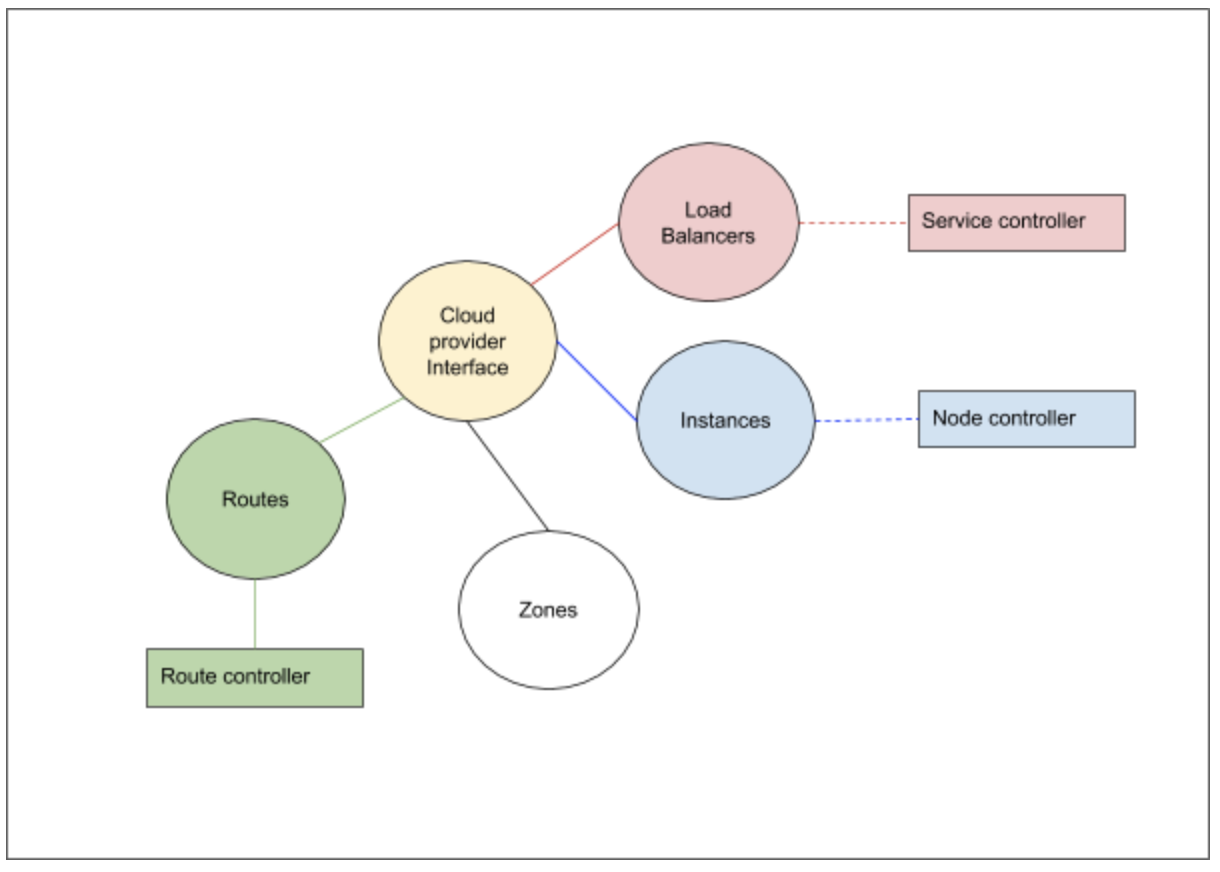
Kubernetes cloud provider interface provides interactions with clouds for managing cloud-specific resources, e.g. public IPs and routes. A good overview of these components is given in [2]. In case of Azure Kubernetes cluster, the Kubernetes interactions go through the Azure cloud provider layer and contact the various services running in the cloud.
The cloud provider implementation of K8s can be largely divided into the following component interfaces which we need to implement:
- Load Balancer
- Instances
- Zones
- Routes
In addition to the above interfaces, the storage services from the cloud provider is linked via the volume plugin layer.
Azure cloud provider implementation and VMSS
In the Azure cloud provider, for every type of cluster we implement, there is a VMType option which we specify. In case of VMSS, the VM type is “vmss”. The provisioning software (acs-engine, in future AKS etc.) would setup these values in /etc/kubernetes/azure.json file. Based on this type, various implementations would get instantiated [3]
The load balancer interface provides access to the underlying cloud provider load balancer service. The information about the load balancers and the control operations on them are required for Kubernetes to handle the services which gets hosted on the Kubernetes cluster. For VMSS support the changes ensure that the VMSS instances are part of the load balancer pool as required.
The instances interfaces help the cloud controller to get various details about a node from the cloud provider layer. For example, the details of a node like the IP address, the instance id etc, is obtained by the controller by means of the instances interfaces which the cloud provider layer registers with it. In case of VMSS support, we talk to VMSS service to gather information regarding the instances.
The zones interfaces help the cloud controller to get zone information for each node. Scheduler could spread pods to different availability zones with such information. It is also required for supporting topology aware dynamic provisioning features, e.g. AzureDisk. Each VMSS instances will be labeled with its current zone and region.
The routes interfaces help the cloud controller to setup advanced routes for Pod network. For example, a route with prefix node’s podCIDR and next hop node’s internal IP will be set for each node. In case of VMSS support, the next hops are VMSS virtual machines’ internal IP address.
The Azure volume plugin interfaces have been modified for VMSS to work properly. For example, the attach/detach to the AzureDisk have been modified to perform these operations at VMSS instance level.
Setting up a VMSS cluster on Azure
The following link [4] provides an example of acs-engine to create a Kubernetes cluster.
acs-engine deploy --subscription-id <subscription id> \
--dns-prefix <dns> --location <location> \
--api-model examples/kubernetes.json
API model file provides various configurations which acs-engine uses to create a cluster. The API model here [5] gives a good starting configuration to setup the VMSS cluster.
Once a VMSS cluster is created, here are some of the steps you can run to understand more about the cluster setup. Here is the output of kubectl get nodes from a cluster created using the above command:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-agentpool1-92998111-vmss000000 Ready agent 1h v1.12.0-rc.2
k8s-agentpool1-92998111-vmss000001 Ready agent 1h v1.12.0-rc.2
k8s-master-92998111-0 Ready master 1h v1.12.0-rc.2
This cluster consists of two worker nodes and one master. Now how do we check which node is which in Azure parlance? In VMSS listing, we can see a single VMSS:
$ az vmss list -o table -g k8sblogkk1
Name ResourceGroup Location Zones Capacity Overprovision UpgradePolicy
---------------------------- --------------- ---------- ------- ---------- --------------- ---------------
k8s-agentpool1-92998111-vmss k8sblogkk1 westus2 2 False Manual
The nodes which we see as agents (in the kubectl get nodes command) are part of this vmss. We can use the following command to list the instances which are part of the VM scale set:
$ az vmss list-instances -g k8sblogkk1 -n k8s-agentpool1-92998111-vmss -o table
InstanceId LatestModelApplied Location Name ProvisioningState ResourceGroup VmId
------------ -------------------- ---------- ------------------------------ ------------------- --------------- ------------------------------------
0 True westus2 k8s-agentpool1-92998111-vmss_0 Succeeded K8SBLOGKK1 21c57d6c-9c8f-4a62-970f-63ed0fcba53f
1 True westus2 k8s-agentpool1-92998111-vmss_1 Succeeded K8SBLOGKK1 840743b9-0076-4a2e-920e-5ba9da296665
The node name does not match the name in the vm scale set, but if we run the following command to list the providerID we can find the matching node which resembles the instance name:
$ kubectl describe nodes k8s-agentpool1-92998111-vmss000000| grep ProviderID
ProviderID: azure:///subscriptions/<subscription id>/resourceGroups/k8sblogkk1/providers/Microsoft.Compute/virtualMachineScaleSets/k8s-agentpool1-92998111-vmss/virtualMachines/0
Current Status and Future
Currently the following is supported:
- VMSS master nodes and worker nodes
- VMSS on worker nodes and Availability set on master nodes combination.
- Per vm disk attach
- Azure Disk & Azure File support
- Availability zones (Alpha)
In future there will be support for the following:
- AKS with VMSS support
- Per VM instance public IP
Cluster Autoscaler
A Kubernetes cluster consists of nodes. These nodes can be virtual machines, bare metal servers or could be even virtual node (virtual kubelet). To avoid getting lost in permutations and combinations of Kubernetes ecosystem ;-), let’s consider that the cluster we are discussing consists of virtual machines, which are hosted in a cloud (eg: Azure, Google or AWS). What this effectively means is that you have access to virtual machines which run Kubernetes agents and a master node which runs k8s services like API server. A detailed version of k8s architecture can be found here [11].
The number of nodes which are required on a cluster depends on the workload on the cluster. When the load goes up there is a need to increase the nodes and when it subsides, there is a need to reduce the nodes and clean up the resources which are no longer in use. One way this can be taken care of is to manually scale up the nodes which are part of the Kubernetes cluster and manually scale down when the demand reduces. But shouldn’t this be done automatically ? Answer to this question is the Cluster Autoscaler (CA).
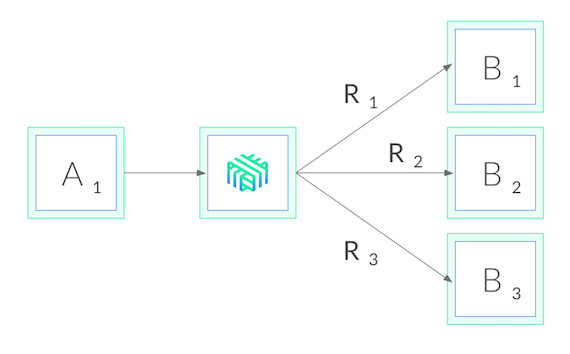
The cluster autoscaler itself runs as a pod within the kubernetes cluster. The following figure illustrates the high level view of the setup with respect to the k8s cluster:
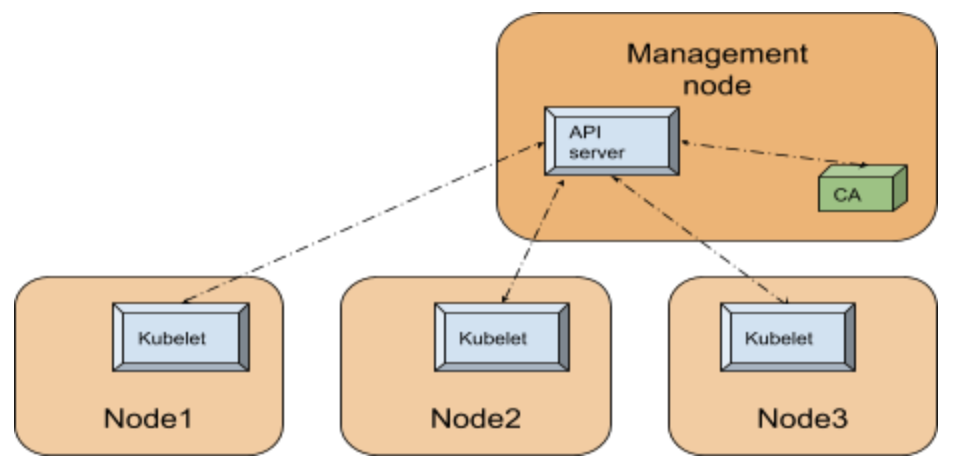
Since Cluster Autoscaler is a pod within the k8s cluster, it can use the in-cluster config and the Kubernetes go client [10] to contact the API server.
Internals
The API server is the central service which manages the state of the k8s cluster utilizing a backing store (an etcd database), runs on the management node or runs within the cloud (in case of managed service such as AKS). For any component within the Kubernetes cluster to figure out the state of the cluster, like for example the nodes registered in the cluster, contacting the API server is the way to go.
In order to simplify our discussion let’s divide the CA functionality into 3 parts as given below:
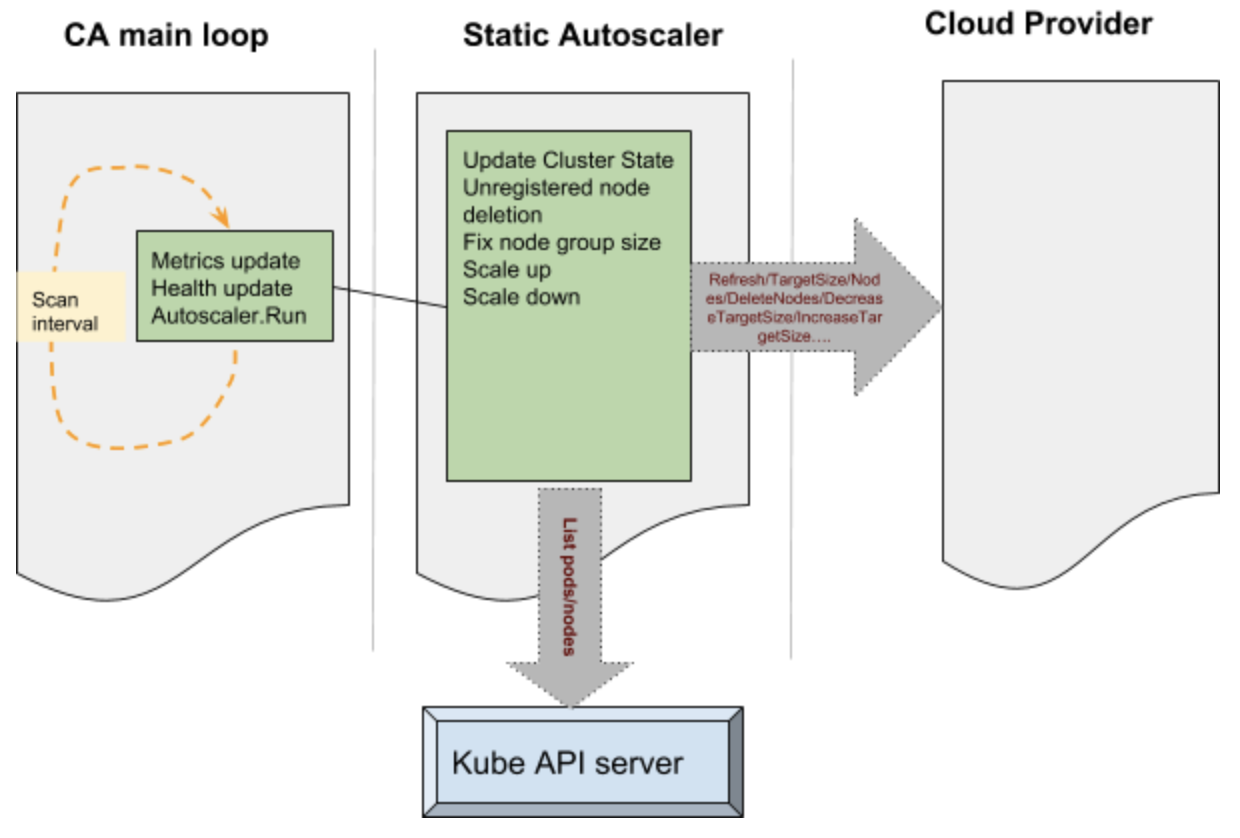
The main portion of the CA is a control loop which keeps running at every scan interval. This loop is responsible for updating the autoscaler metrics and health probes. Before this loop is entered auto scaler performs various operations such as claiming the leader state after performing a Kubernetes leader election. The main loop initializes static autoscaler component. This component initializes the underlying cloud provider based on the parameters passed onto the CA.
Various operations performed by the CA to manage the state of the cluster is passed onto the cloud provider component. Some examples like – increase target size, decrease target size etc, results in the cloud provider component talking to the cloud services internally and performing operations such as adding a node or deleting a node. These operations are performed on group of nodes in the cluster. The static autoscaler also keeps tab on the state of the system by querying the API server – operations such as list pods and list nodes are used to get hold of such information.
The decision to make a scale up is based on pods which remain unscheduled and a variety of checks and balances. The nodes which are free to be scaled down are deleted from the cluster and deleted from the cloud itself. The cluster autoscaler applies checks and balances before scaling up and scaling down – for example the nodes which have been recently added are given special consideration. During the deletion the nodes are drained to ensure that no disruption happens to the running pods.
Setting up CA on Azure:
Cluster Autoscaler is available as an add-on with acs-engine. The following link [15] has an example configuration file used to deploy autoscaler with acs-engine. The following link [8] provides details on manual step by step way to do the same.
In acs-engine case we use the regular command line to deploy:
acs-engine deploy --subscription-id <subscription id> \
--dns-prefix <dns> --location <location> \
--api-model examples/kubernetes.json
The main difference are the following lines in the config file at [15] makes sure that CA is deployed as an addon:
"addons": [
{
"name": "cluster-autoscaler",
"enabled": true,
"config": {
"minNodes": "1",
"maxNodes": "5"
}
}
]
The config section in the json above can be used to provide the configuration to the cluster autoscaler pod, eg: min and max nodes as above.
Once the setup completes we can see that the cluster-autoscaler pod is deployed in the system namespace:
$kubectl get pods -n kube-system | grep autoscaler
cluster-autoscaler-7bdc74d54c-qvbjs 1/1 Running 1 6m
Here is the output from the CA configmap and events from a sample cluster:
$kubectl -n kube-system describe configmap cluster-autoscaler-status
Name: cluster-autoscaler-status
Namespace: kube-system
Labels: <none>
Annotations: cluster-autoscaler.kubernetes.io/last-updated=2018-10-02 01:21:17.850010508 +0000 UTC
Data
====
status:
----
Cluster-autoscaler status at 2018-10-02 01:21:17.850010508 +0000 UTC:
Cluster-wide:
Health: Healthy (ready=3 unready=0 notStarted=0 longNotStarted=0 registered=3 longUnregistered=0)
LastProbeTime: 2018-10-02 01:21:17.772229859 +0000 UTC m=+3161.412682204
LastTransitionTime: 2018-10-02 00:28:49.944222739 +0000 UTC m=+13.584675084
ScaleUp: NoActivity (ready=3 registered=3)
LastProbeTime: 2018-10-02 01:21:17.772229859 +0000 UTC m=+3161.412682204
LastTransitionTime: 2018-10-02 00:28:49.944222739 +0000 UTC m=+13.584675084
ScaleDown: NoCandidates (candidates=0)
LastProbeTime: 2018-10-02 01:21:17.772229859 +0000 UTC m=+3161.412682204
LastTransitionTime: 2018-10-02 00:39:50.493307405 +0000 UTC m=+674.133759650
NodeGroups:
Name: k8s-agentpool1-92998111-vmss
Health: Healthy (ready=2 unready=0 notStarted=0 longNotStarted=0 registered=2 longUnregistered=0 cloudProviderTarget=2 (minSize=1, maxSize=5))
LastProbeTime: 2018-10-02 01:21:17.772229859 +0000 UTC m=+3161.412682204
LastTransitionTime: 2018-10-02 00:28:49.944222739 +0000 UTC m=+13.584675084
ScaleUp: NoActivity (ready=2 cloudProviderTarget=2)
LastProbeTime: 2018-10-02 01:21:17.772229859 +0000 UTC m=+3161.412682204
LastTransitionTime: 2018-10-02 00:28:49.944222739 +0000 UTC m=+13.584675084
ScaleDown: NoCandidates (candidates=0)
LastProbeTime: 2018-10-02 01:21:17.772229859 +0000 UTC m=+3161.412682204
LastTransitionTime: 2018-10-02 00:39:50.493307405 +0000 UTC m=+674.133759650
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScaleDownEmpty 42m cluster-autoscaler Scale-down: removing empty node k8s-agentpool1-92998111-vmss000002
As can be seen the events, the cluster autoscaler scaled down and deleted a node as there was no load on this cluster. The rest of the configmap in this case indicates that there are no further actions which the autoscaler is taking at this moment.
Current status and future:
Cluster Autoscaler currently supports four VM types: standard (VMAS), VMSS, ACS and AKS. In the future, Cluster Autoscaler will be integrated within AKS product, so that users can enable it by one-click.
User Assigned Identity
Inorder for the Kubernetes cluster components to securely talk to the cloud services, it needs to authenticate with the cloud provider. In Azure Kubernetes clusters, up until now this was done using two ways – Service Principals or Managed Identities. In case of service principal the credentials are stored within the cluster and there are password rotation and other challenges which user needs to incur to accommodate this model. Managed service identities takes out this burden from the user and manages the service instances directly [12].
There are two kinds of managed identities possible – one is system assigned and another is user assigned. In case of system assigned identity each vm in the Kubernetes cluster is assigned a managed identity during creation. This identity is used by various Kubernetes components needing access to Azure resources. Examples to these operations are getting/updating load balancer configuration, getting/updating vm information etc. With the system assigned managed identity, user has no control over the identity which is assigned to the underlying vm. The system automatically assigns it and this reduces the flexibility for the user.
With v1.12 we bring user assigned managed identity support for Kubernetes. With this support user does not have to manage any passwords but at the same time has the flexibility to manage the identity which is used by the cluster. For example if the user needs to allow access to a cluster for a specific storage account or a Azure key vault, the user assigned identity can be created in advance and key vault access provided.
Internals
To understand the internals, we will focus on a cluster created using acs-engine. This can be configured in other ways, but the basic interactions are of the same pattern.
The acs-engine sets up the cluster with the required configuration. The /etc/kubernetes/azure.json file provides a way for the cluster components (eg: kube-apiserver) to gather configuration on how to access the cloud resources. In a user managed identity cluster there is a value filled with the key as UserAssignedIdentityID. This value is filled with the client id of the user assigned identity created by acs-engine or provided by the user, however the case may be. The code which does the authentication for Kubernetes on azure can be found here [14]. This code uses Azure adal packages to get authenticated to access various resources in the cloud. In case of user assigned identity the following API call is made to get new token:
adal.NewServicePrincipalTokenFromMSIWithUserAssignedID(msiEndpoint,
env.ServiceManagementEndpoint,
config.UserAssignedIdentityID)
This calls hits either the instance metadata service or the vm extension [12] to gather the token which is then used to access various resources.
Setting up a cluster with user assigned identity
With the upstream support for user assigned identity in v1.12, it is now supported in the acs-engine to create a cluster with the user assigned identity. The json config files present here [13] can be used to create a cluster with user assigned identity. The same step used to create a vmss cluster can be used to create a cluster which has user assigned identity assigned.
acs-engine deploy --subscription-id <subscription id> \
--dns-prefix <dns> --location <location> \
--api-model examples/kubernetes-msi-userassigned/kube-vmss.json
The main config values here are the following:
"useManagedIdentity": true
"userAssignedID": "acsenginetestid"
The first one useManagedIdentity indicates to acs-engine that we are going to use the managed identity extension. This sets up the necessary packages and extensions required for the managed identities to work. The next one userAssignedID provides the information on the user identity which is to be used with the cluster.
Current status and future
Currently we support the user assigned identity creation with the cluster using deploy of the acs-engine. In future this will become part of AKS.
Get involved
For azure specific discussions – please checkout the Azure SIG page at [6] and come and join the #sig-azure slack channel for more.
For CA, please checkout the Autoscaler project here [7] and join the #sig-autoscaling Slack for more discussions.
For the acs-engine (the unmanaged variety) on Azure docs can be found here: [9]. More details about the managed service from Azure Kubernetes Service (AKS) here [5].
References
1) https://docs.microsoft.com/en-us/azure/virtual-machine-scale-sets/overview
2) https://kubernetes.io/docs/concepts/architecture/cloud-controller/
3) https://github.com/kubernetes/kubernetes/blob/master/pkg/cloudprovider/providers/azure/azure_vmss.go
4) https://github.com/Azure/acs-engine/blob/master/docs/kubernetes/deploy.md
5) https://docs.microsoft.com/en-us/azure/aks/
6) https://github.com/kubernetes/community/tree/master/sig-azure
7) https://github.com/kubernetes/autoscaler
8) https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/azure/README.md
9) https://github.com/Azure/acs-engine
10) https://github.com/kubernetes/client-go
11) https://kubernetes.io/docs/concepts/architecture/
12) https://docs.microsoft.com/en-us/azure/active-directory/managed-identities-azure-resources/overview
13) https://github.com/Azure/acs-engine/tree/master/examples/kubernetes-msi-userassigned
14) https://github.com/kubernetes/kubernetes/blob/master/pkg/cloudprovider/providers/azure/auth/azure_auth.go
15) https://github.com/Azure/acs-engine/tree/master/examples/addons/cluster-autoscaler